 Frikipandi – Web de Tecnología – Lo más Friki de la red. Web de Tecnología con las noticias más frikis de Internet. Noticias de gadgets, Hardware, Software, móviles e Internet. Frikipandi
Frikipandi – Web de Tecnología – Lo más Friki de la red. Web de Tecnología con las noticias más frikis de Internet. Noticias de gadgets, Hardware, Software, móviles e Internet. Frikipandi 
Secretos del algoritmo: se ha filtrado la documentación de ingeniería interna de la Búsqueda de Google. Pues ahora va a ser verdad que Google tiene un sistema para valorar la autoridad de los domininios. Sorpresa para los SEO.
Google, si estás leyendo esto, es demasiado tarde. 😉Es broma pero era algo que intuiamos los SEO de medios.
De acuerdo. Se crujen los nudillos . Vayamos directo al grano. Se filtró documentación interna para la API Content Warehouse de la Búsqueda de Google. Los microservicios internos de Google parecen reflejar lo que ofrece Google Cloud Platform y la versión interna de la documentación para el obsoleto Document AI Warehouse se publicó accidentalmente en un repositorio de código de la biblioteca del cliente. La documentación de este código también fue capturada por un servicio de documentación automatizado externo.
Según el historial de cambios, este error del repositorio de código se solucionó el 7 de mayo, pero la documentación automatizada aún está activa. En un esfuerzo por limitar la posible responsabilidad, no lo vincularé aquí, pero debido a que todo el código en ese repositorio se publicó bajo la licencia Apache 2.0 , a cualquiera que lo encontrara se le concedió un amplio conjunto de derechos, incluida la capacidad de usar , modificarlo y distribuirlo de todos modos.
Revisé los documentos de referencia de API y los contextualicé con algunas otras filtraciones anteriores de Google y el testimonio antimonopolio del Departamento de Justicia. Estoy combinando eso con la extensa investigación de patentes y documentos técnicos realizada para mi próximo libro, The Science of SEO . Si bien no hay detalles sobre las funciones de puntuación de Google en la documentación que he revisado, existe una gran cantidad de información sobre los datos almacenados para contenido, enlaces e interacciones de los usuarios. También hay diversos grados de descripciones (que van desde decepcionantemente escasas hasta sorprendentemente reveladoras) de las características que se manipulan y almacenan.
Estaría tentado a llamarlos en términos generales “factores de clasificación”, pero eso sería impreciso. Muchos, incluso la mayoría, de ellos son factores de clasificación, pero muchos no lo son. Lo que haré aquí es contextualizar algunos de los sistemas y características de clasificación más interesantes (al menos, los que pude encontrar en las primeras horas de revisión de esta filtración masiva) en base a mi extensa investigación y las cosas que Google me ha dicho. nos mintió a lo largo de los años.
«Mentir» es duro, pero es la única palabra precisa que se puede utilizar aquí. Si bien no necesariamente culpo a los representantes públicos de Google por proteger su información patentada, sí discrepo de sus esfuerzos por desacreditar activamente a personas en los mundos del marketing, la tecnología y el periodismo que han presentado descubrimientos reproducibles. Mi consejo para los futuros empleados de Google que hablen sobre estos temas: a veces es mejor decir simplemente «no podemos hablar de eso». Su credibilidad importa, y cuando salen a la luz filtraciones como ésta y testimonios como el del juicio del Departamento de Justicia, resulta imposible confiar en sus declaraciones futuras.
LAS ADVERTENCIAS
Creo que todos sabemos que la gente trabajará para desacreditar mis hallazgos y análisis de esta filtración. Algunos se preguntarán por qué es importante y dirán «pero eso ya lo sabíamos». Entonces, dejemos de lado las advertencias antes de pasar a lo bueno.
- Tiempo y contexto limitados: con el fin de semana festivo, solo he podido pasar unas 12 horas aproximadamente en profunda concentración en todo esto. Estoy increíblemente agradecido con algunas partes anónimas que fueron de gran ayuda al compartir sus ideas conmigo para ayudarme a ponerme al día rápidamente. Además, al igual que la filtración de Yandex que cubrí el año pasado , no tengo una imagen completa. Donde teníamos código fuente para analizar y ninguna de las ideas detrás de Yandex, en este caso tenemos algunas de las ideas detrás de miles de características y módulos, pero ningún código fuente. Tendrán que perdonarme por compartir esto de una manera menos estructurada de lo que lo haré unas semanas después de haberme sentado más tiempo con el material.
- Sin funciones de puntuación: no sabemos cómo se ponderan las características en las distintas funciones de puntuación posteriores. No sabemos si se está utilizando todo lo disponible. Sabemos que algunas funciones están obsoletas. A menos que se indique explícitamente, no sabemos cómo se utilizan las cosas. No sabemos dónde sucede todo en el proceso. Tenemos una serie de sistemas de clasificación con nombres que se alinean vagamente con la forma en que Google los ha explicado, cómo los SEO han observado las clasificaciones en la naturaleza y cómo las solicitudes de patentes y la literatura de relaciones internacionales lo explican. En última instancia, gracias a esta filtración, ahora tenemos una imagen más clara de lo que se está considerando y que puede informar en qué nos centramos y en qué ignoramos en el SEO en el futuro.
- Probablemente la primera de varias publicaciones: esta publicación será mi intento inicial de lo que he revisado. Es posible que publique publicaciones posteriores a medida que continúo profundizando en los detalles. Sospecho que este artículo hará que la comunidad de SEO se apresure a analizar estos documentos y, colectivamente, descubriremos y recontextualizaremos cosas en los próximos meses.
- Esto parece ser información actual: lo mejor que puedo decir es que esta filtración representa la arquitectura activa actual del almacenamiento de contenido de búsqueda de Google a partir de marzo de 2024. (Indique a una persona de relaciones públicas de Google que dice que estoy equivocado. En realidad, saltémonos la canción). y bailar, todos ustedes). Según el historial de confirmaciones, el código relacionado se introdujo el 27 de marzo de 2024 y no se eliminó hasta el 7 de mayo de 2024.
- Correlación no es causalidad . Bueno, esto realmente no se aplica aquí, pero solo quería asegurarme de cubrir todas las bases.
HAY FUNCIONES DE CLASIFICACIÓN DE 14K Y MÁS EN LOS DOCUMENTOS
Hay 2596 módulos representados en la documentación de la API con 14.014 atributos (características) que se ven así:

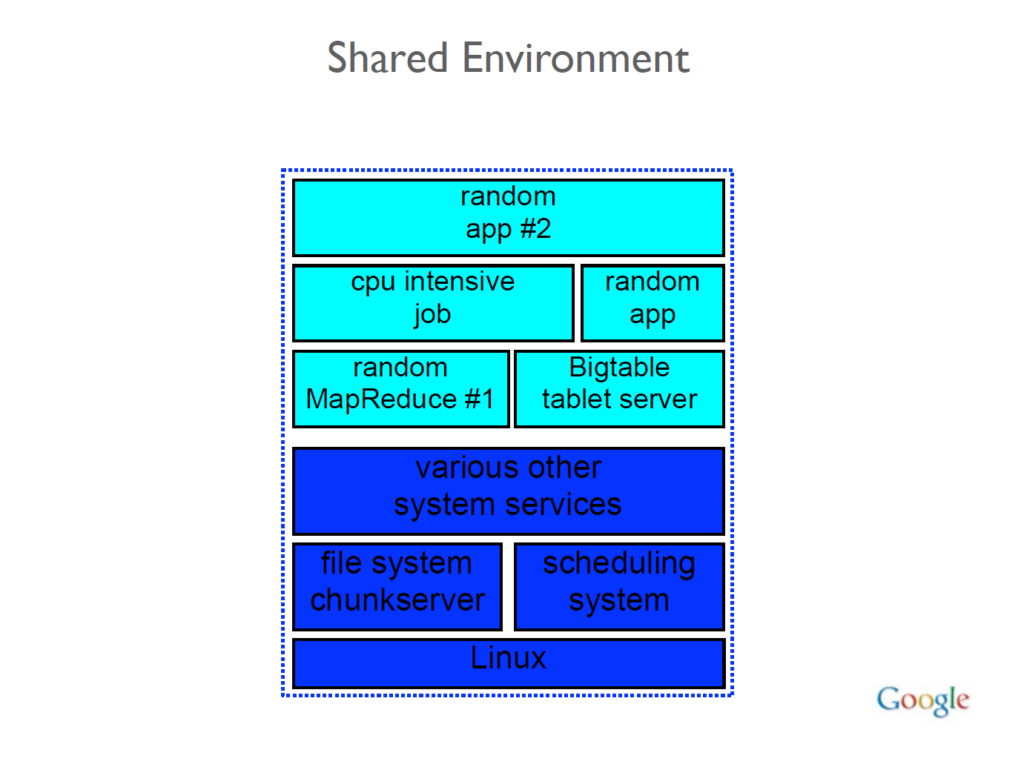
Los módulos están relacionados con componentes de YouTube, Asistente, Libros, búsqueda de videos, enlaces, documentos web, infraestructura de rastreo, un sistema de calendario interno y People API. Al igual que Yandex, los sistemas de Google operan en un repositorio monolítico (o “monorepo”) y las máquinas operan en un entorno compartido. Esto significa que todo el código se almacena en un solo lugar y cualquier máquina de la red puede formar parte de cualquiera de los sistemas de Google.
La documentación filtrada describe cada módulo de la API y los divide en resúmenes, tipos, funciones y atributos. La mayor parte de lo que estamos viendo son las definiciones de propiedades para varios buffers de protocolo (o protobufs) a los que se accede a través de los sistemas de clasificación para generar SERP (páginas de resultados del motor de búsqueda: lo que Google muestra a los buscadores después de realizar una consulta).
Desafortunadamente, muchos de los resúmenes hacen referencia a enlaces Go, que son URL en la intranet corporativa de Google, que ofrecen detalles adicionales para diferentes aspectos del sistema. Sin las credenciales de Google correctas para iniciar sesión y ver estas páginas (lo que casi con seguridad requeriría ser un Googler actual en el equipo de Búsqueda), nos vemos abandonados a nuestra propia interpretación.
LOS DOCUMENTOS API REVELAN ALGUNAS MENTIRAS NOTABLES DE GOOGLE
Los portavoces de Google han hecho todo lo posible para desviarnos y engañarnos sobre una variedad de aspectos de cómo operan sus sistemas en un esfuerzo por controlar cómo nos comportamos como SEO. No iré tan lejos como para llamarlo “ingeniería social” debido a la cargada historia de ese término. En lugar de eso, vayamos con… «gaslighting». Las declaraciones públicas de Google probablemente no sean esfuerzos intencionales para mentir, sino más bien para engañar a potenciales spammers (y también a muchos SEO legítimos) para desviarnos de cómo impactar los resultados de búsqueda.
A continuación, presento afirmaciones de los empleados de Google junto con datos de la documentación con comentarios limitados para que puedas juzgar por ti mismo.
«No tenemos nada parecido a la autoridad de dominio»
Los portavoces de Google han dicho en numerosas ocasiones que no utilizan la «autoridad de dominio». Siempre he asumido que esto era una mentira por omisión y ofuscación.
Al decir que no usan la autoridad de dominio, podrían estar diciendo que específicamente no usan la métrica de Moz llamada «Autoridad de dominio» (obviamente 🙄). También podrían estar diciendo que no miden la autoridad o la importancia de un tema (o dominio) específico en relación con un sitio web. Esta confusión semántica les permite nunca responder directamente a la pregunta de si calculan o utilizan métricas de autoridad en todo el sitio.
Gary Ilyes, analista del equipo de búsqueda de Google que se centra en publicar información para ayudar a los creadores de sitios web, ha repetido esta afirmación en numerosas ocasiones.
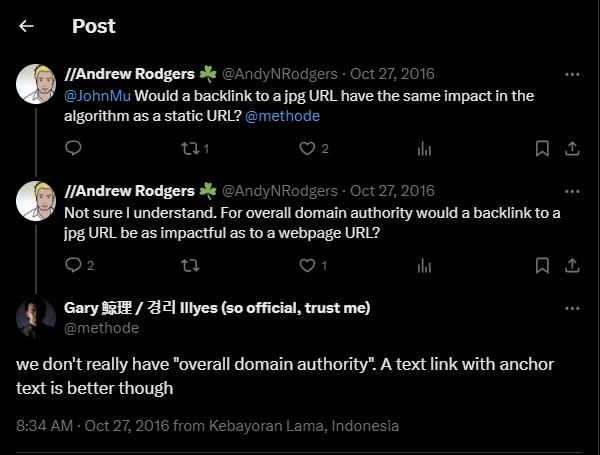
Y Gary no está solo. John Mueller, un «defensor de las búsquedas que coordina las relaciones de búsqueda de Google» declaró en este vídeo «no tenemos puntuación de autoridad del sitio web».
En realidad, como parte de las señales de calidad comprimidas que se almacenan por documento, Google tiene una función que calcula llamada «siteAuthority».
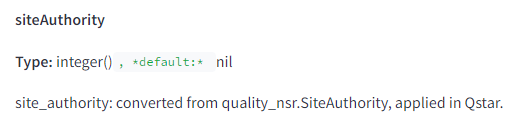
No sabemos específicamente cómo se calcula o utiliza esta medida en las funciones de puntuación posteriores, pero ahora sabemos definitivamente que existe y se utiliza en el sistema de clasificación Q*. Resulta que Google sí tiene una autoridad de dominio general. Indique a los empleados de Google decir «lo tenemos, pero no lo usamos» o «no entiendes lo que eso significa» o… espera, dije «comentarios limitados», ¿no? Hacia adelante.
«No utilizamos clics para las clasificaciones»
Dejemos esto en cama para siempre.
El testimonio de Pandu Nayak en el juicio antimonopolio del Departamento de Justicia reveló recientemente la existencia de los sistemas de clasificación Glue y NavBoost. NavBoost es un sistema que emplea medidas basadas en clics para mejorar, degradar o reforzar de otro modo una clasificación en la búsqueda web. Nayak indicó que Navboost existe desde aproximadamente 2005 e históricamente utilizó 18 meses consecutivos de datos de clics. El sistema se actualizó recientemente para utilizar 13 meses consecutivos de datos y se centra en los resultados de búsqueda web, mientras que un sistema llamado Glue está asociado con otros resultados de búsqueda universales. Pero, incluso antes de esa revelación, teníamos varias patentes (incluida la patente de Clasificación basada en el tiempo de 2007 ) que indica específicamente cómo se pueden utilizar los registros de clics para cambiar los resultados.
También sabemos que los clics como medida de éxito son una buena práctica en la recuperación de información . Sabemos que Google ha optado por algoritmos impulsados por el aprendizaje automático y que el aprendizaje automático requiere variables de respuesta para perfeccionar su rendimiento. A pesar de esta asombrosa evidencia, todavía hay confusión en la comunidad SEO debido a la mala dirección de los portavoces de Google y la publicación vergonzosamente cómplice de artículos en todo el mundo del marketing de búsqueda que repiten acríticamente las declaraciones públicas de Google.
Gary Ilyes ha abordado este problema de medición de clics muchas veces. En un caso, reforzó lo que el ingeniero de búsqueda de Google Paul Haahr compartió en su charla de SMX West de 2016 sobre experimentos en vivo, diciendo que «usar clics directamente en las clasificaciones sería un error».

Más tarde aún, utilizó su plataforma para menospreciar a Rand Fishkin (fundador/CEO de Moz y practicante de SEO desde hace mucho tiempo) diciendo que «el tiempo de espera, el CTR, cualquiera que sea la nueva teoría de Fishkin, generalmente son una tontería inventada».
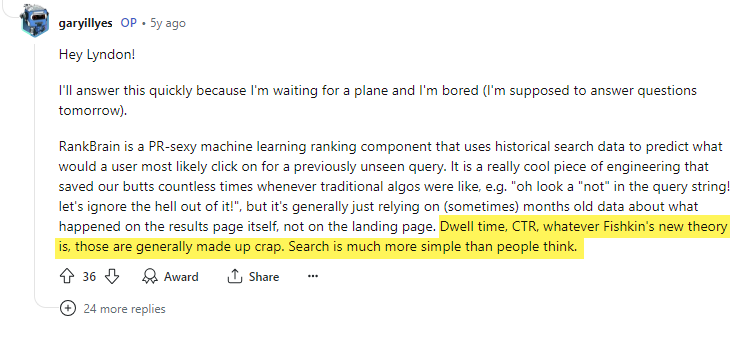
En realidad, Navboost dispone de un módulo específico íntegramente centrado en las señales de clic.
El resumen de ese módulo lo define como “señales de clics e impresiones para Craps”, uno de los sistemas de clasificación. Como vemos a continuación, los clics malos, los clics buenos, los últimos clics más largos, los clics no aplastados y los últimos clics más largos no aplastados se consideran métricas. Según la patente de Google «Puntuación de resultados de búsqueda locales según la prominencia de la ubicación» , «la aplastación es una función que evita que una señal grande domine a las demás». En otras palabras, los sistemas están normalizando los datos de clic para garantizar que no haya una manipulación descontrolada basada en la señal de clic. Los empleados de Google argumentan que los sistemas en patentes y documentos técnicos no son necesariamente los que están en producción, pero sería absurdo construir e incluir NavBoost si no fuera una parte crítica de los sistemas de recuperación de información de Google.
Fuente https://ipullrank.com/google-algo-leak
. Leer artículo completo en Frikipandi Secretos del algoritmo: se ha filtrado la documentación de ingeniería interna de la Búsqueda de Google.




